[ELK] ML 학습해보기
회사에서 ML기능을 학습해 보는 시간을 가져보았습니다.
문제 Task는 다음과 같습니다.
2020~2022년 6월말까지의 JSON데이터 (서비스센터의 차량데이터)
| CENTER | RO | CUST_SEQ | CUST_TYPE | CPS_3YR_PROPO | VISIT_3YR_PROPO | VIN | SALES_TYPE | BRAND | HEV | HP | TAKING_FIX | VEHICLE_AGE_PROPO | MILEAGE_PROPO | GR_BP | KPI_CATEGORY | 12V | TIRE | EFA | Air Care |
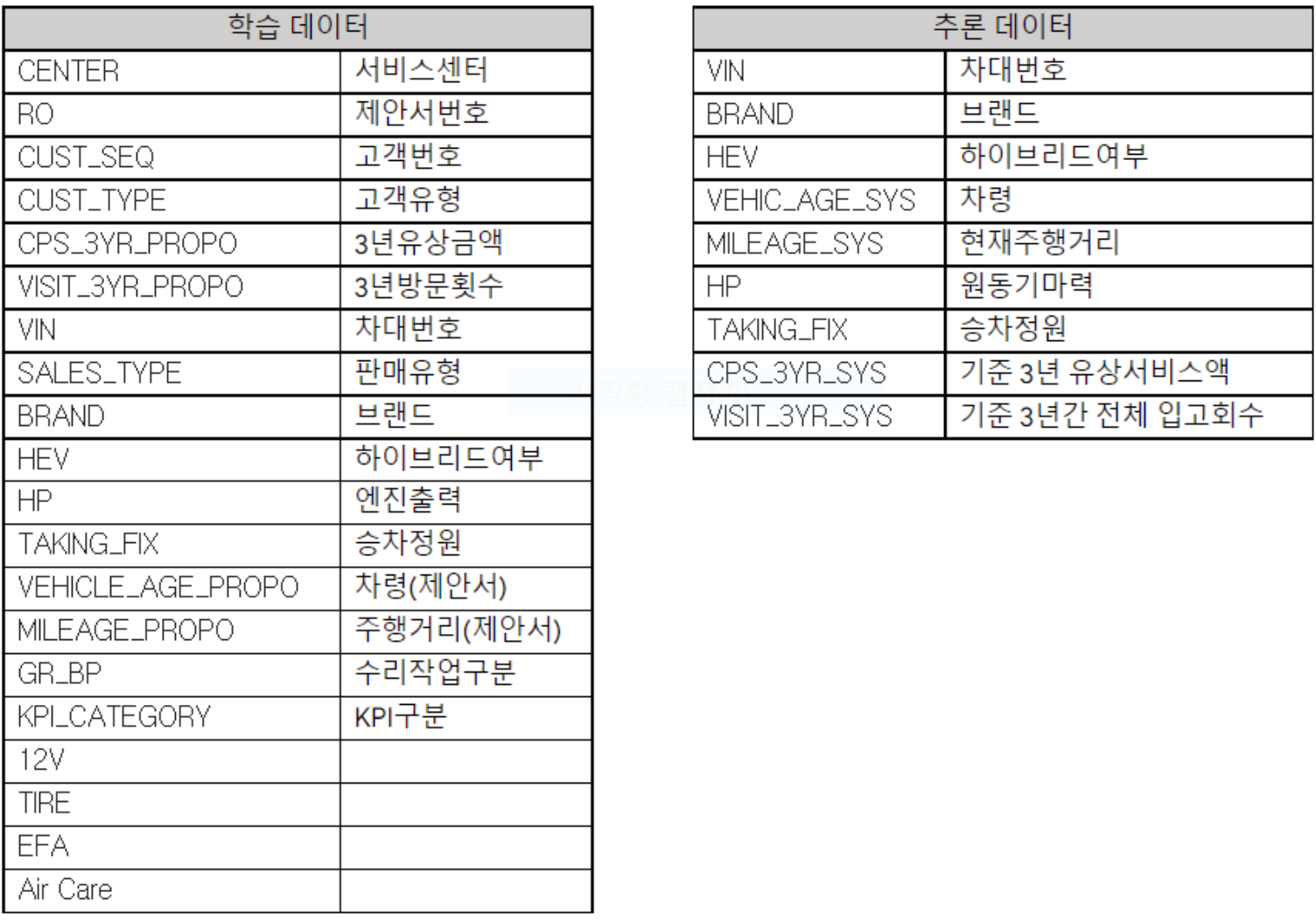
컬럼중에 EFA가 있다.
EFA란? 유상옵션 적용 유무를 의미
이 데이터를 학습해서 2022년 07월 EFA 옵션을 적용했을까 안 해놨을까를
예측해 보고 상관관계 분석(추론)해본다
- Hint!) 7월 달 거 잘라서 사용하면 된다. 차대 번호로는 원하는 값을 얻어서 쓸 수 없다.
참고로 머신러닝은 클라우드나 30일 트라이얼을 동의해야 사용 가능하다.
머신러닝 > 데이터프레임 분석 > 탐색 시각화 해볼 수 있다.
ML에 알고리즘이 4가지가 있다.
이상탐지, 아웃라이어, 클래스피케이션, 레그리션 네 가지가 있는데 이중에 나는 classficationd을 이용했다.
데이터
⬝ 학습 데이터 : train_rosa_pre_data.csv (2020.08~2022.06) - 290585건
⬝ 예측 대상 데이터 : test_rosa_pre_data.csv (2022.07) - 12544건
데이터 정제
1. 날짜 필드 정제
입고 순서 제거, Python의 datetime 형식으로 변경
2020-08-01(1) > 2020-08-01
2. 차대번호 필드 분리
- 차량 특성(CHARACTERISTICS)
- 생산년도(MODEL_YEAR)
2가지 필드 생성

3. target 변수 0, 1로 바꿔줌
Null -> 0
‘EFA’ -> 1
4. 필요 없는 필드 제거
12V, TIRE, Air Care, RO (처음 날짜가 있던 필드) 필드 삭제
12V, TIRE, Air Care : Null 값이 많고 유료고객 예측에 필요 없다고 판단
모델
1. Elastic에 데이터 import 후 Data Frame Analytics > Jobs > Create job
2. Classification model train & 결과 확인
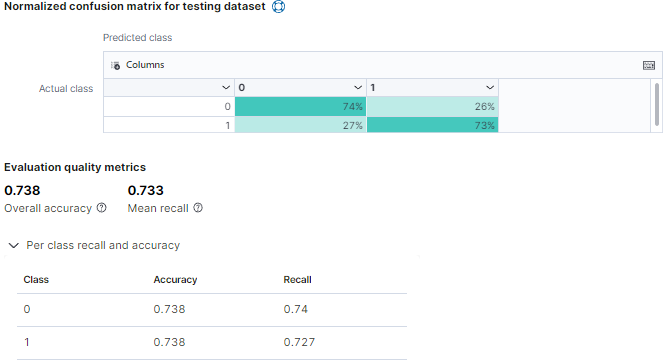
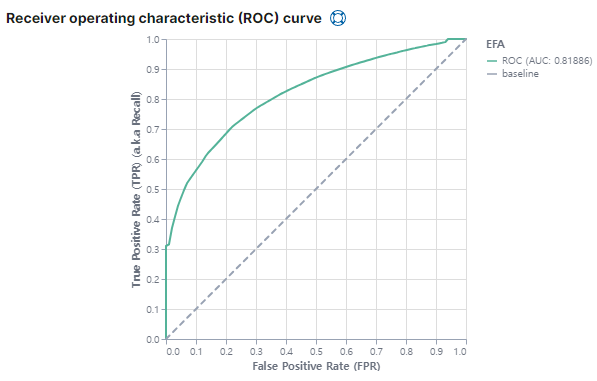
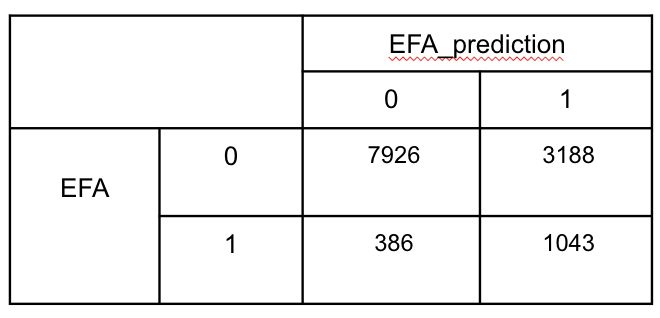
예측 결과
1) 방법
학습 결과 Deploy -> ingest pipeline 형성
미리 import 한 test data를 pipeline 통과

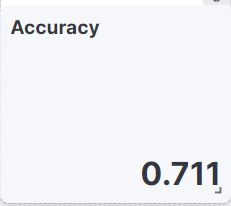
2) 정확도
- * dash board
(count(kql='EFA :0 and ml.inference.EFA_prediction.EFA_prediction :0')+ count(kql='EFA :1 and ml.inference.EFA_prediction.EFA_prediction:1'))/
count()
- Confusion Matrix