
Notice
Recent Posts
Recent Comments
Link
250x250
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- 리눅스
- 제이쉘
- JShell
- 기초코딩
- 프로그래밍
- eclips
- 코딩초보
- 프로그래밍기초
- 자바
- 스프링
- 메소드
- 자바 스프링
- Java
- Elk
- 이클립스
- github
- 초보코딩
- 클래스
- 초보코딩탈출
- Git
- 알고리즘
- 자바기초
- 배열
- 컴퓨터과학개론
- 프로그래밍언어
- JAVA기초
- 데이터베이스
- spring
- 스프링 기초
- 자바프로그래밍
Archives
- Today
- Total
키보드워리어
[python,beautifulsoup4]웹크롤러 뷰티풀수프 기초 본문
728x90
python으로 라이브러리를 설치후 사용
쥬피터를 사용했을때 한줄 씩 실행해서
값을 찾아가는 과정이 재밌고 편하다.
맨처음 URL을 설정후 가져와 본다.
해볼것은 루마썬팅 faq 자료
# URL 설정
url = "http://www.llumar.co.kr/sub_bbs/bbs_list.php?curr_page=25&bcode=9&list_count=20&sch_option=&sch_str="
됐는지 확인해볼까
response = requests.get(url)
if response.status_code == 200: # 페이지가 존재하는 경우
response.encoding = 'euc-kr' # 한글 깨짐 방지
soup = BeautifulSoup(response.text, 'html.parser')참고로 쥬피터에서는 soup 로 만 쳐도 바로바로 결과값을 볼 수 있기 때문에 편하다
# 테이블 행 추출
rows = soup.select('tr')추출결과
<tr>
<th class="hidden-phone" style="text-align:center;">No.</th>
<th style="text-align:center;">제 목</th>
<th class="hidden-phone" style="text-align:center;">작성일</th>
<th class="hidden-phone" style="text-align:center;">조 회</th>
</tr>No: NOTICE
Title: [공지] 루마버텍스는 미국 제조원의 정식제품입니다
Date: 2022.10.31
Views: 12539
값은 이렇다.
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL 설정 (페이지 번호가 1부터 n까지)
base_url = "http://llumar.co.kr/sub_support/faq.php?curr_page={}&list_count=20&sch_str=&sch_cate="
data = []
# 페이지 순회
for page_num in range(1, 2):
url = base_url.format(page_num)
response = requests.get(url)
if response.status_code == 200: # 페이지가 존재하는 경우
response.encoding = 'euc-kr' # 한글 깨짐 방지
soup = BeautifulSoup(response.text, 'html.parser')
# 테이블 행 추출
rows = soup.select('tr')
# 행 반복 처리
for row in rows:
cols = row.find_all('td')
if len(cols) == 4:
no = cols[0].text.strip()
importance = cols[1].text.strip()
question_field = cols[2].text.strip()
question = cols[3].text.strip()
data.append([no, importance, question_field, question])
# 데이터프레임 생성
df = pd.DataFrame(data, columns=['No.', '중요도', '질문분야', '질문'])
# 데이터프레임 출력 및 저장
df.to_csv("faq_scraping_results.csv", index=False, encoding='utf-8-sig')
print(df)
크롤링할때 한개의 상품에서 여러개의 상품으로 체크를하는게 좋다.
값을 보면서 하려면 쥬피터가 편하다
하나의 나무를 선택 후 숲으로 나아가는 과정이라고 생각하자
이 때 CSS 선택자에 대한 기본적인 지식만 갖고 있음 좋다
- 한개의 상품
- css 선택자
- tag 선택
- class 선택 .
- id 선택 #
- 자식선택 >
- css 선택자
선택자에 대한 기호이고 선택자는 html태그 내에서 확인 가능하다.
한개의 상품 > 여러개의 상품 > 여러 웹페이지 크롤링으로 단계를 넓히자.

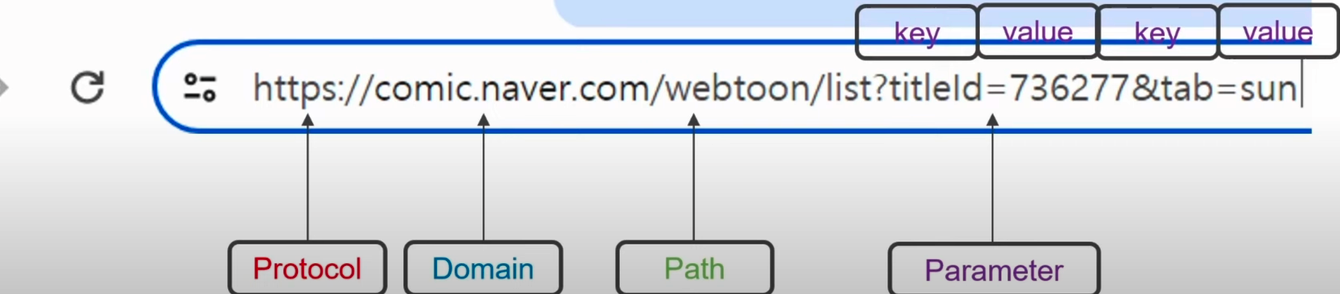
페이지를 바꾸어가면 URL이 변경되는 부분을 찾아 볼 수 있다. 이렇게 변경된 부분을 찾으면 여러 웹페이지 크롤링까지 가능하다(구조가 같을 경우)
728x90